
다양한 기법을 사용하는 리스크 매트릭스 제작
1. R 및 ggplot2를 사용하는 리스크 매트릭스 도표 작성
이 포스트에서는 R과 ggplot2를 사용하여 여러 태스크에서의 시간적 영향, 가능성 및 코스트를 시각화하여 리스크 매트릭스를 만드는 방법을 알아봅니다.
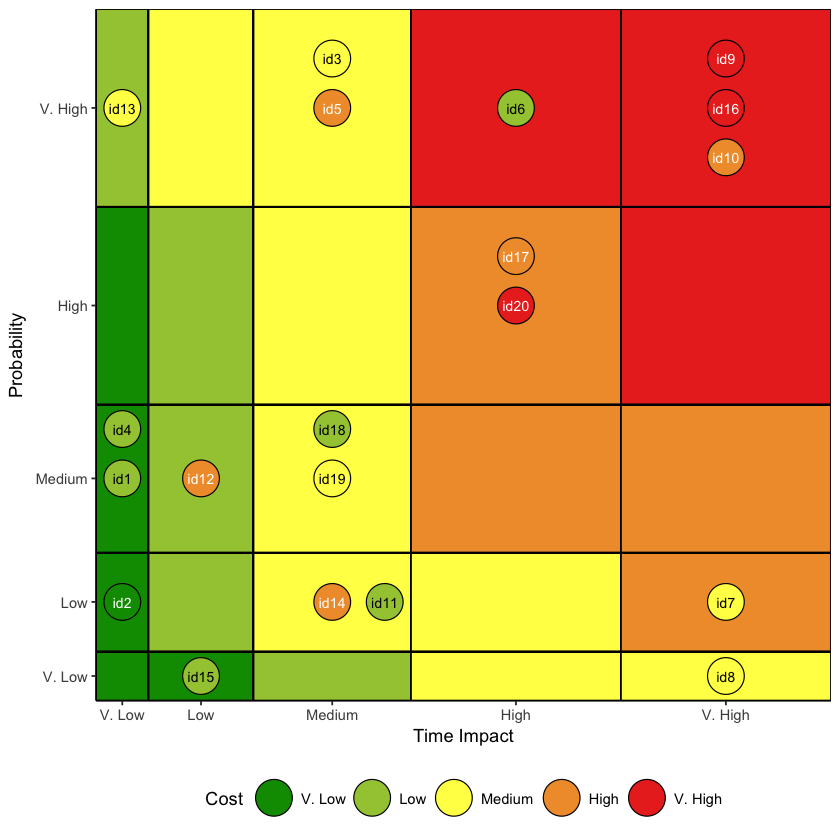
완성된 도표는 다음과 같습니다.
불러온 자료를 이용해 시작합니다. 이 포스트에서는 ggplot2와 scales를 사용합니다.
In[1]:
library(ggplot2)
library(scales)
1(가장 심각하지 않음)부터 5(가장 심각함) 사이의 시간 영향, 가능성 및 코스트로 분류된 태스크의 데이터 세트를 불러옵니다.
In[2]:
dataset <- read.csv("risk_matrix_data.csv")
head(dataset)
| task_id | time_impact | probability | cost |
|---|---|---|---|
| id1 | 1 | 3 | 2 |
| id2 | 1 | 2 | 1 |
| id3 | 3 | 5 | 3 |
| id4 | 1 | 3 | 2 |
| id5 | 3 | 5 | 4 |
| id6 | 4 | 5 | 2 |
플롯은 0과 420 사이에서 나타나며 이러한 형태의 도표는 더 심각한 리스크를 향해 섹션 크기가 커지므로 오른쪽 위로 높은 리스크가 나타나게 됩니다.
아래의 코드는 경계를 정의하고 각 구간의 중점을 계산합니다.
In[3]:
min_1 <- 0
min_2 <- 30
min_3 <- 90
min_4 <- 180
min_5 <- 300
max_plot = 420
mid_1 <- ((min_2 - min_1) / 2) + min_1
mid_2 <- ((min_3 - min_2) / 2) + min_2
mid_3 <- ((min_4 - min_3) / 2) + min_3
mid_4 <- ((min_5 - min_4) / 2) + min_4
mid_5 <- ((max_plot - min_5) / 2) + min_5
mid_values <- data.frame("val"= c(1, 2, 3, 4, 5), "midpoint"=c(mid_1, mid_2, mid_3, mid_4, mid_5))
x축은 리스크 섹션의 중간 점으로부터 time_impact_pos 의 위치를 계산합니다.
마찬가지로 y축에 probability_pos 위치에 대해 동일한 작업을 수행합니다.
In[4]:
dataset <- merge(x=dataset, y=mid_values, by.x="time_impact", by.y="val")
names(dataset)[names(dataset) == 'midpoint'] <- 'time_impact_pos'
dataset <- merge(x=dataset, y=mid_values, by.x="probability", by.y="val")
names(dataset)[names(dataset) == 'midpoint'] <- 'probability_pos'
동일 섹션에 복수의 리스크가 있을 수 있으므로 충돌이 발생하지 않도록 리스크의 위치를 오프셋 하기 위해 각 리스크가 있는 섹션 번호를 계산해야 합니다.
그 다음 각 섹션의 누적 합을 사용해 내재된 리스크의 수를 계산할 수 있습니다.
시간 영향(x)이 가능성(y)보다 크다면 섹션이 넓고 짧은 섹션이 될 수 있으므로 위치를 왼쪽이나 오른쪽으로 오프셋 해야 합니다.
시간 영향(x)이 가능성(y)보다 작으면 좁고 긴 섹션이 될 수있으므로 위치를 위 또는 아래로 오프셋해야합니다.
동일 섹션에서 최대 7개 리스크를 수용하도록 오프셋을 정의합니다.
In[5]:
dataset$section_no <- dataset$time_impact + (dataset$probability - 1) * 5
dataset <- dataset[order(dataset$section_no,-dataset$cost),]
dataset$section_no_count <- ave(dataset$section_no==dataset$section_no, dataset$section_no, FUN=cumsum)
position_offset <- 30
# 오프셋이 0이 되도록 초기화
dataset$time_impact_pos_offset <- 0
dataset$probability_pos_offset <- 0
# 동일 구간에 2개의 리스크가 있거나,
# x < y 일때, y의 위치를 올린다.
dataset$probability_pos_offset[
(dataset$section_no_count == 2) &
(dataset$time_impact <= dataset$probability)
] <- position_offset
# 동일 구간에 2개의 리스크가 있거나,
# x > y 일때, x의 위치를 올린다.
dataset$time_impact_pos_offset[
(dataset$section_no_count == 2) &
(dataset$time_impact > dataset$probability)
] <- position_offset
# 동일 구간에 3개의 리스크가 있거나,
# x < y일때, 3번째 리스크를 위해 y의 위치를 내린다.
dataset$probability_pos_offset[
(dataset$section_no_count == 3) &
(dataset$time_impact <= dataset$probability)
] <- -position_offset
# 동일 구간에 3개의 리스크가 있거나,
# x > y일때, 3번째 리스크를 위해 y의 위치를 내린다.
dataset$time_impact_pos_offset[
(dataset$section_no_count == 3) &
(dataset$time_impact > dataset$probability)
] <- -position_offset
# 4, 5번째 리스크를 위해 수직 이동
dataset$probability_pos_offset[
(dataset$section_no_count == 4) &
(dataset$time_impact > dataset$probability)
] <- position_offset
dataset$time_impact_pos_offset[
(dataset$section_no_count == 4) &
(dataset$time_impact <= dataset$probability)
] <- position_offset
dataset$probability_pos_offset[
(dataset$section_no_count == 5) &
(dataset$time_impact > dataset$probability)
] <- -position_offset
dataset$time_impact_pos_offset[
(dataset$section_no_count == 5) &
(dataset$time_impact <= dataset$probability)
] <- -position_offset
# 6,7번째 리스크를 위해 x,y를 동시에 오프셋
dataset$probability_pos_offset[dataset$section_no_count == 6] <- position_offset
dataset$time_impact_pos_offset[dataset$section_no_count == 6] <- position_offset
dataset$probability_pos_offset[dataset$section_no_count == 7] <- -position_offset
dataset$time_impact_pos_offset[dataset$section_no_count == 7] <- -position_offset
코스트의 값은 범주형이므로 정렬된 요소와 코스트에 의미 있는 이름을 부여합니다.
이러한 다른 코스트 레벨은 각각 다른 전경색에 대응될것이기에 이러한 전경색에 어울리는 텍스트 색을 필요로 합니다. 따라서 코스트가 “낮음”(밝은 녹색) 또는 “중간”(노란색)일 경우 검은색 텍스트를 사용해 읽기 좋게 해줍니다.
In[6]
dataset$cost <- factor(dataset$cost, ordered=TRUE)
factor_values <- c("V. Low", "Low", "Medium", "High", "V. High")
levels(dataset$cost) <- c("V. Low", "Low", "Medium", "High", "V. High")
dataset$text_color <- "white"
dataset$text_color[dataset$cost=="Low" | dataset$cost=="Medium"] <- "black"
이제 플롯을 준비합니다. 아래의 코드는 섹션마다 다른 전경색을 대응시킵니다.
In[7]
# 색 지정
dark_green <- '#009900'
light_green <- '#A4C93F'
yellow <- '#FFFD54'
orange <- '#F19C38'
red <- '#EA3224'
# 플롯 초기화
# x, y깂 은 x, y의 위치.
# 오프셋으로 인해 충돌되지 않도록 오프셋
p <- ggplot(dataset,
aes(x = time_impact_pos + time_impact_pos_offset,
y = probability_pos + probability_pos_offset,
fill = cost
)
)
# 기본값 제거
p<-p+theme_classic()
# x, y축 라벨링
p <- p + xlab('Time Impact')
p <- p + ylab('Probability')
# x축을 0부터 420으로 스케일
# 축에 대한 구분선 정의
# 적정 값으로 눈금의 라벨 정의
# 최소 최대 점을 넘는 축으로 확장해서는 안 됨
p <- p + scale_x_continuous(
limits=c(min_1, max_plot),
breaks = c(mid_1, mid_2, mid_3, mid_4, mid_5),
labels = factor_values,
expand=c(0, 0)
)
# y축 복사
p <- p + scale_y_continuous(
limits=c(min_1, max_plot),
breaks = c(mid_1, mid_2, mid_3, mid_4, mid_5),
labels = factor_values,
expand=c(0, 0)
)
# 각 사각형 섹션에 대한 전경색 지정
#Row 1 Rects
p <- p + geom_rect(xmin=min_1, xmax=min_2, ymin=min_1, ymax=min_2, fill=dark_green, size=0.5, color='black')
p <- p + geom_rect(xmin=min_2, xmax=min_3, ymin=min_1, ymax=min_2, fill=dark_green, size=0.5, color='black')
p <- p + geom_rect(xmin=min_3, xmax=min_4, ymin=min_1, ymax=min_2, fill=light_green, size=0.5, color='black')
p <- p + geom_rect(xmin=min_4, xmax=min_5, ymin=min_1, ymax=min_2, fill=yellow, size=0.5, color='black')
p <- p + geom_rect(xmin=min_5, xmax=max_plot, ymin=min_1, ymax=min_2, fill=yellow, size=0.5, color='black')
#Row 2 Rects
p <- p + geom_rect(xmin=min_1, xmax=min_2, ymin=min_2, ymax=min_3, fill=dark_green, size=0.5, color='black')
p <- p + geom_rect(xmin=min_2, xmax=min_3, ymin=min_2, ymax=min_3, fill=light_green, size=0.5, color='black')
p <- p + geom_rect(xmin=min_3, xmax=min_4, ymin=min_2, ymax=min_3, fill=yellow, size=0.5, color='black')
p <- p + geom_rect(xmin=min_4, xmax=min_5, ymin=min_2, ymax=min_3, fill=yellow, size=0.5, color='black')
p <- p + geom_rect(xmin=min_5, xmax=max_plot, ymin=min_2, ymax=min_3, fill=orange, size=0.5, color='black')
#Row 3 Rects
p <- p + geom_rect(xmin=min_1, xmax=min_2, ymin=min_3, ymax=min_4, fill=dark_green, size=0.5, color='black')
p <- p + geom_rect(xmin=min_2, xmax=min_3, ymin=min_3, ymax=min_4, fill=light_green, size=0.5, color='black')
p <- p + geom_rect(xmin=min_3, xmax=min_4, ymin=min_3, ymax=min_4, fill=yellow, size=0.5, color='black')
p <- p + geom_rect(xmin=min_4, xmax=min_5, ymin=min_3, ymax=min_4, fill=orange, size=0.5, color='black')
p <- p + geom_rect(xmin=min_5, xmax=max_plot, ymin=min_3, ymax=min_4, fill=orange, size=0.5, color='black')
#Row 4 Rects
p <- p + geom_rect(xmin=min_1, xmax=min_2, ymin=min_4, ymax=min_5, fill=dark_green, size=0.5, color='black')
p <- p + geom_rect(xmin=min_2, xmax=min_3, ymin=min_4, ymax=min_5, fill=light_green, size=0.5, color='black')
p <- p + geom_rect(xmin=min_3, xmax=min_4, ymin=min_4, ymax=min_5, fill=yellow, size=0.5, color='black')
p <- p + geom_rect(xmin=min_4, xmax=min_5, ymin=min_4, ymax=min_5, fill=orange, size=0.5, color='black')
p <- p + geom_rect(xmin=min_5, xmax=max_plot, ymin=min_4, ymax=min_5, fill=red, size=0.5, color='black')
#Row 5 Rects
p <- p + geom_rect(xmin=min_1, xmax=min_2, ymin=min_5, ymax=max_plot, fill=light_green, size=0.5, color='black')
p <- p + geom_rect(xmin=min_2, xmax=min_3, ymin=min_5, ymax=max_plot, fill=yellow, size=0.5, color='black')
p <- p + geom_rect(xmin=min_3, xmax=min_4, ymin=min_5, ymax=max_plot, fill=yellow, size=0.5, color='black')
p <- p + geom_rect(xmin=min_4, xmax=min_5, ymin=min_5, ymax=max_plot, fill=red, size=0.5, color='black')
p <- p + geom_rect(xmin=min_5, xmax=max_plot, ymin=min_5, ymax=max_plot, fill=red, size=0.5, color='black')
# 플롯 분산형 차트
# 경계가 있는 원을 사용
# id를 읽을 수 있을 만큼의 크기 지정
p <- p + geom_point(shape=21, size=10)
# 점은 코스트의 값을 기반으로 지정됨
fill_colors <- c("V. Low" = dark_green, "Low" = light_green, "Medium" = yellow, "High" = orange, "V. High" = red)
p <- p + scale_fill_manual(values = fill_colors, name="Cost")
# 점의 전경색을 id 라벨에 따라 지정
p <- p + geom_text(aes(label=task_id), size=3, hjust=0.5, vjust=0.5, color=dataset$text_color)
# 바닥에 범주 위치
p <- p +theme(
legend.position = "bottom"
)
# 플롯 출력
print(p)
참고:
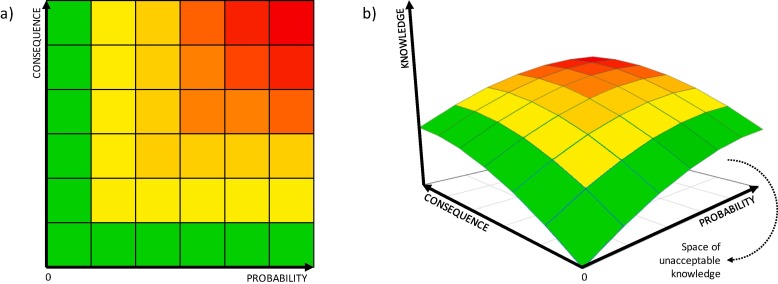
a) 2차원 리스크 매트릭스, b) 3차원 리스크 매트릭스
(Learning about risk: Machine learning for risk assessment:
Nicola Paltrinieri, Louise Comfort, Genserik Reniers)
원문: CREATING A RISK MATRIX GRAPHIC USING R AND GGPLOT2 by Ben Alex Keen
https://benalexkeen.com/creating-a-risk-matrix-graphic-using-r-and-ggplot2/
2. Python 및 NetworkX를 사용하는 리스크 그래프 작성
Python과 NetworkX를 사용하여 복잡한 네트워크의 구조 역학 및 기능의 생성, 조작을 위해 NetworkX를 사용해 시각화된 리스크 매트릭스를 만드는 방법을 알아봅니다.
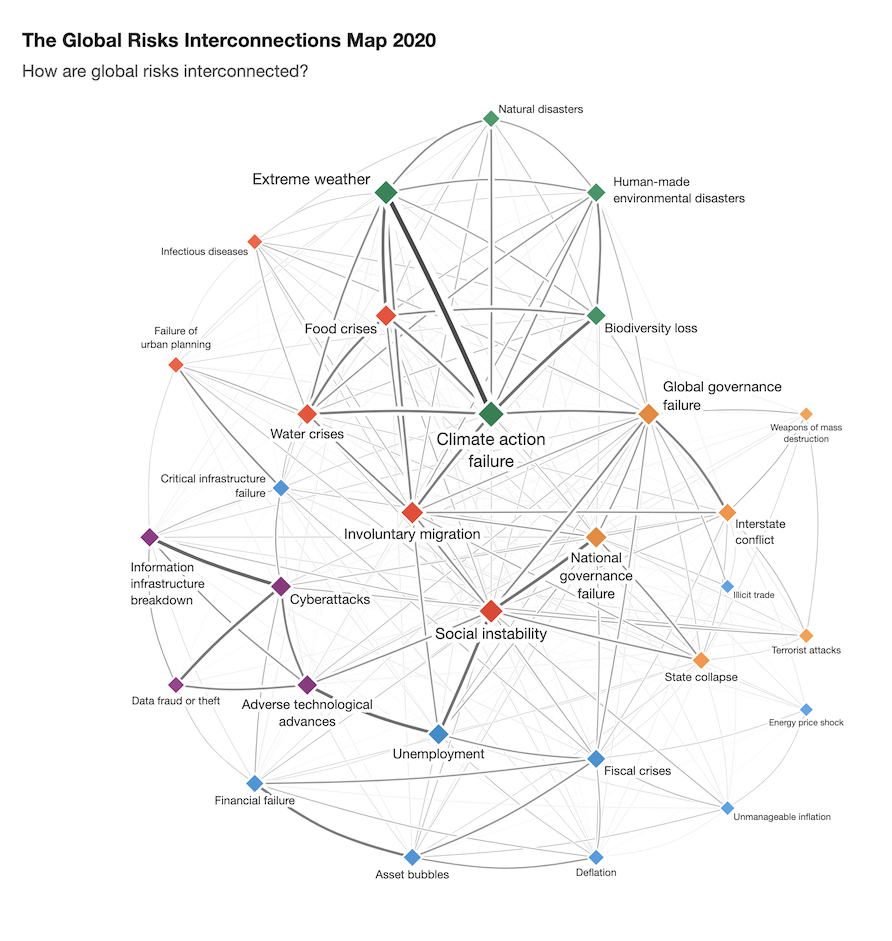
예시는 다음과 같습니다.
(The Global Risks Interconnections: World Economic Forum Report)
Github 에서 불러온 예제 데이터를 이용해 시작합니다.
# 라이브러리 가져오기
import pandas as pd
import numpy as np
import networkx as nx
import matplotlib.pyplot as plt
from matplotlib.colors import LinearSegmentedColormap
# 파일 가져오기 및 데이터 미리보기
all_risks=pd.read_excel(r”path/Risk Data.xlsx”)
cdata = pd.read_excel(r”path/Color Data.xlsx”)
all_risks.head()#RiskData
cdata.head() #MetaData
#가져온 데이터의 속성
all_risks.info()
# 고위험도 적색, 중간 위험도 황색, 저위험도 청색으로
# 리스크 맵 분석을 위한 색상맵 정의
cmap = LinearSegmentedColormap.from_list('mycmap', ['#983228', '#239b56', '#e67e22'])
fig, ax = plt.subplots()
im = ax.imshow(np.random.random((10, 10)), cmap=cmap, interpolation='nearest')
fig.colorbar(im)
plt.show()
# 원점(orign)을 정의 하기위해 열 데이터를 사용하며 연결된 리스크(Connected Risk)는 target
# 생성된 그래프를 확인하기 위해 nx.info사용. Risk는 33개 노드 Connected Risk는 85개 에지
G=nx.from_pandas_edgelist(all_risks, source = ‘Risk’, target = ‘Connected Risk’, create_using=nx.Graph() )
print(nx.info(G))
#만들어진 데이터의 가능성과 심각도를 시각화합니다.
#고위험도, 중간 위험도, 저위험도를 0,1,2로 범주화.
risk_rating= cdata[[‘Risk’, ‘Impact’]].set_index(‘Risk’)
risk_rating.head()
risk_rating[‘myvalue’]=pd.Categorical(risk_rating[‘Impact’])
# 노드 크기는 위험 가능성을 나타냅니다.
# 이미 정의된 위험도와 사용자 정의된 크기(Likelihood)를사용해 노드의 크기를 지정합니다.(확인필요)
node_sizes = cdata[[‘Risk’, ‘Likelihood’]].set_index(‘Risk’)
node_sizes=node_sizes.reindex(G.nodes())
node_sizes[‘myvalue’]=pd.Categorical(node_sizes[‘Likelihood’])
node_sizes['myvalue']
# 에지의 두께는 크기는 연결 강도를 나타냅니다.
# 예제에서는 3가지 범주를 사용해 에지의 두께를 지정합니다.강(10),중(5),약(1)
strength_of_connection = all_risks[[‘Risk’, ‘Strength of Connection’]].set_index(‘Risk’)
node_sizes=node_sizes.reindex(G.nodes())
strength_of_connection['Strength of Connection']=pd.Categorical(strength_of_connection['Strength of Connection'])
strength_of_connection_color = list(strength_of_connection['Strength of Connection'].replace({1:"#f4d03f", 5: "#f1c40f", 10: "#d4ac0d"}))[:85]
# 위에서 정의된 매개변수를 통해 nx.draw를 호출합니다.
# 이때 nx.fruchterman_reingold_layout는 그래프의 레이아웃이다. 그외의 레이아웃 형태는 참고자료를 참조.
plt.figure(3,figsize=(20,20),facecolor = ‘#ededed’)
nx.draw(G, with_labels=True, node_color=risk_rating[‘myvalue’].cat.codes, node_size=node_sizes[‘myvalue’], width=list(strength_of_connection[‘Strength of Connection’]), cmap=cmap, font_size=14,font_family=’sans-serif’, font_color = ‘black’, edge_color = strength_of_connection_color, pos=nx.fruchterman_reingold_layout(G))
plt.show()
레이아웃 참고자료
https://networkx.org/documentation/networkx-1.11/reference/drawing.html#layout
원문: Graph Algorithms for Risk Assessment by Stephen Sanwo
https://python.plainenglish.io/graph-algorithms-for-risk-assessment-9a039abf4cd8
댓글남기기