
그리드맵 폴리곤에 지도 정보 매핑하기
일정 간격으로 샘플링된 지역의 점수 산정을 위해 경위도로 샘플링된 여러 자료의 점수를 합산해야 한다.
모든 샘플을 적절하게 수용 가능한 그리드를 생성 후 데이터를 mapping해 점수를 합산한다면 특정 지역권의 최종 점수를 알 수 있게 된다.
이때 지도를 그리드에 매핑하는 방법은 여러 가지가 있다.
0.1. 그리드 생성
벡터 -> 조사 도구 -> 그리드 생성
0.2. 교차영역 도구
만들어진 그리드와 지도를 교차영역 도구 처리하여 그리드를 지도의 형태로 자르는 방법이 있다.
그러나 이 경우 그리드가 지도 외곽 영역에 맞추어 잘리기에 사각형 형태를 유지하지 못하게 되고 이 경우 추가적인 지도 데이터를 자동 병합할 수 없다는 단점을 가지고 있다.
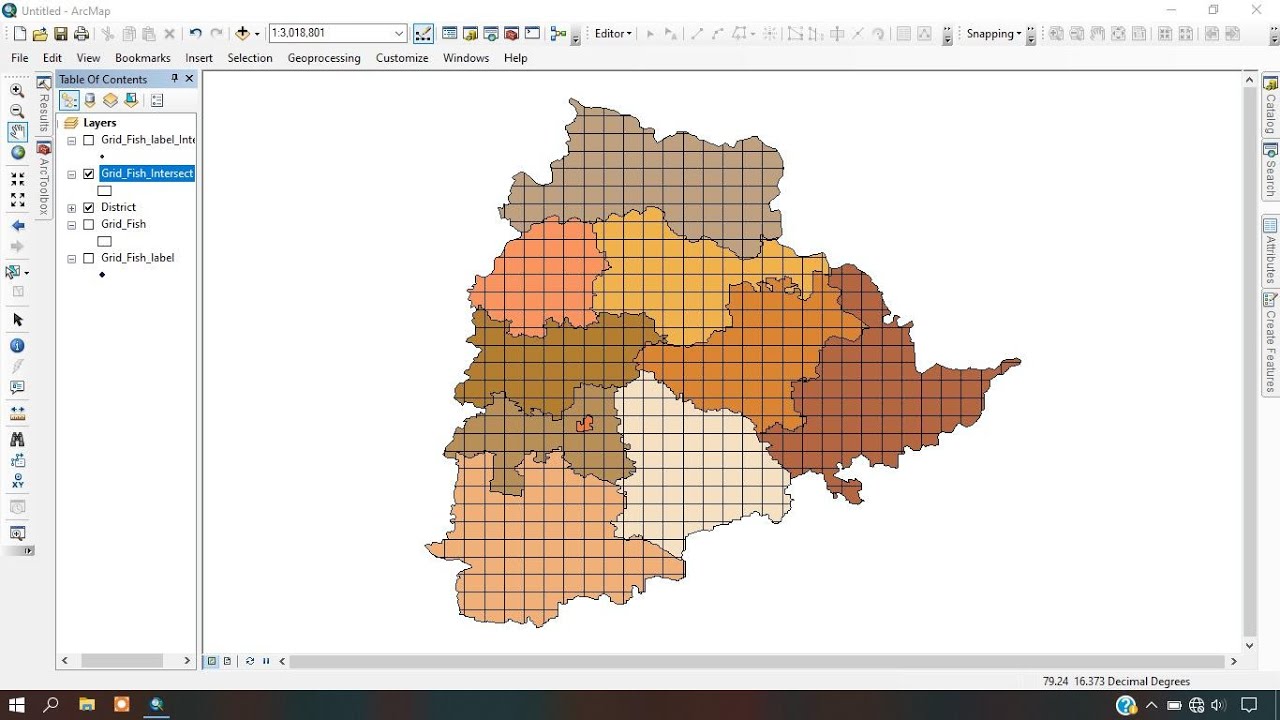
0.3. 선택영역 추출 도구
레이어의 모든 폴리곤을 분리한 후 선택영역 추출 도구를 사용해 지도에서 선택된 영역을 그리드로 추출하는 방법이 있다.
이 경우에는 단일 폴리곤은 문제가 없지만 다중 폴리곤의 경우는 폴리곤이 중첩되는 경우 그리드의 셀이 겹치는 문제를 일으키게 된다.
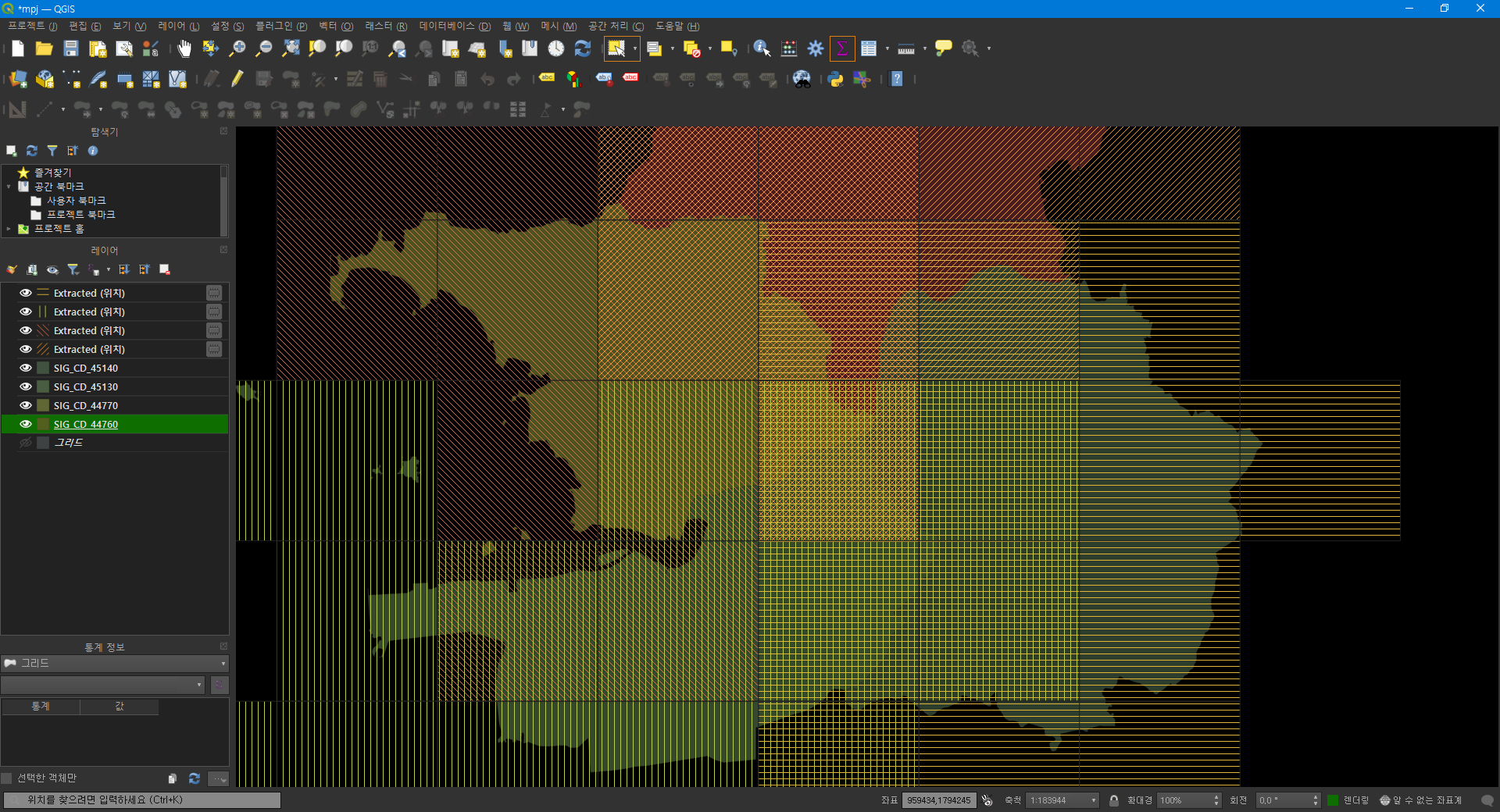
이러한 문제를 해결하기 위해서는 중복 영역을 제거해야 함을 알 수 있다.
1. 파이썬 스크립트를 이용한 비율 기반 추출
그리드 내 셀의 대표지역을 산정하여 한국 시군구 데이터를 공백이나 중첩 없이 fitting 해 그리드에 매핑한 시도에 관해 설명한다.
지도데이터는 다음 자료를 사용한다. http://www.gisdeveloper.co.kr/?p=2332
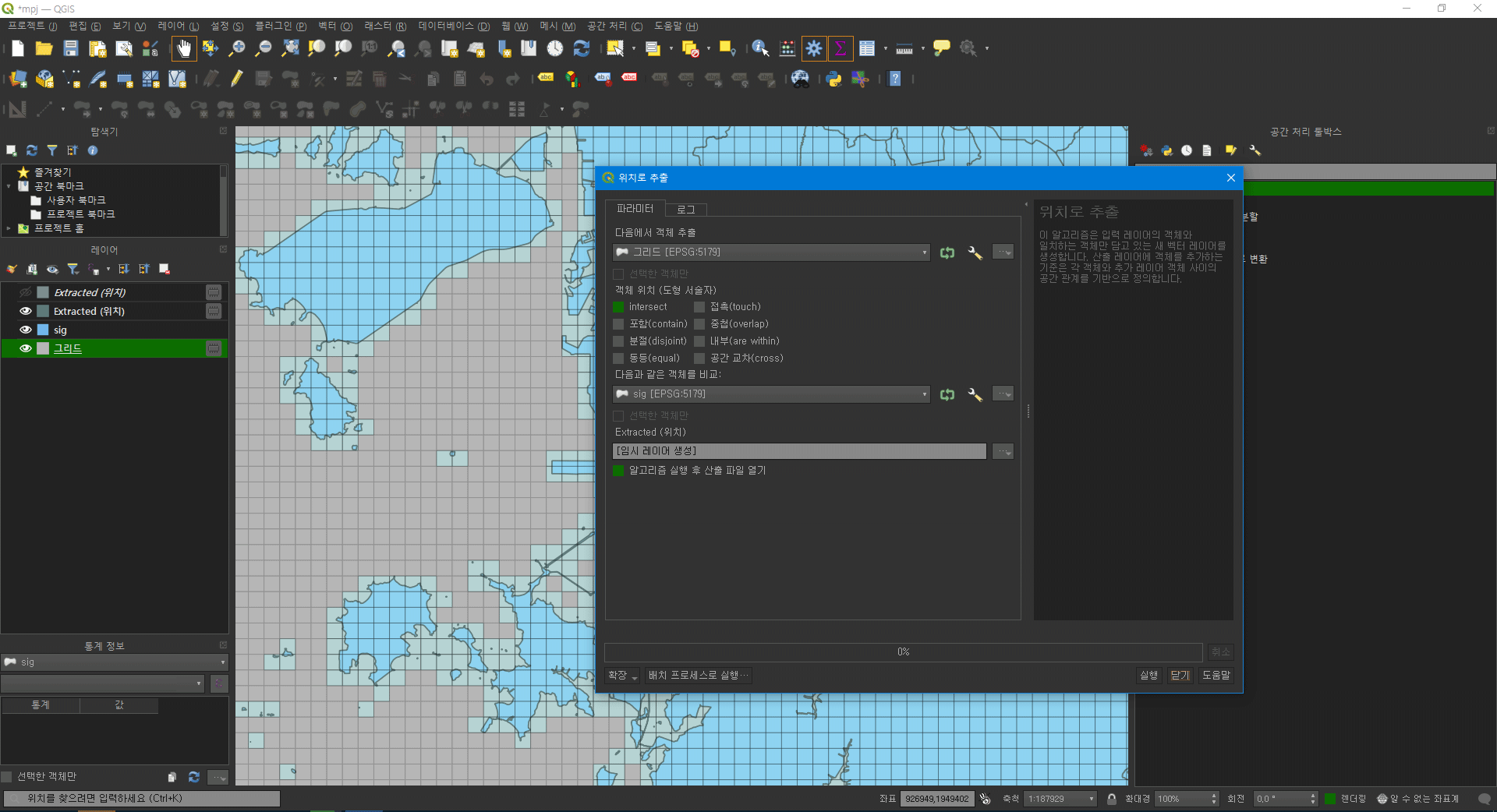
1.1. 지도 최외곽 그리드 생성
QGIS에서 그리드를 생성하고 ‘선택 영역 추출’을 통해 지도 외곽선에 맞춘 그리드를 생성한다. 이는 관련 없는 구역을 미리 제거해 불필요한 연산을 줄이는 절차이다.
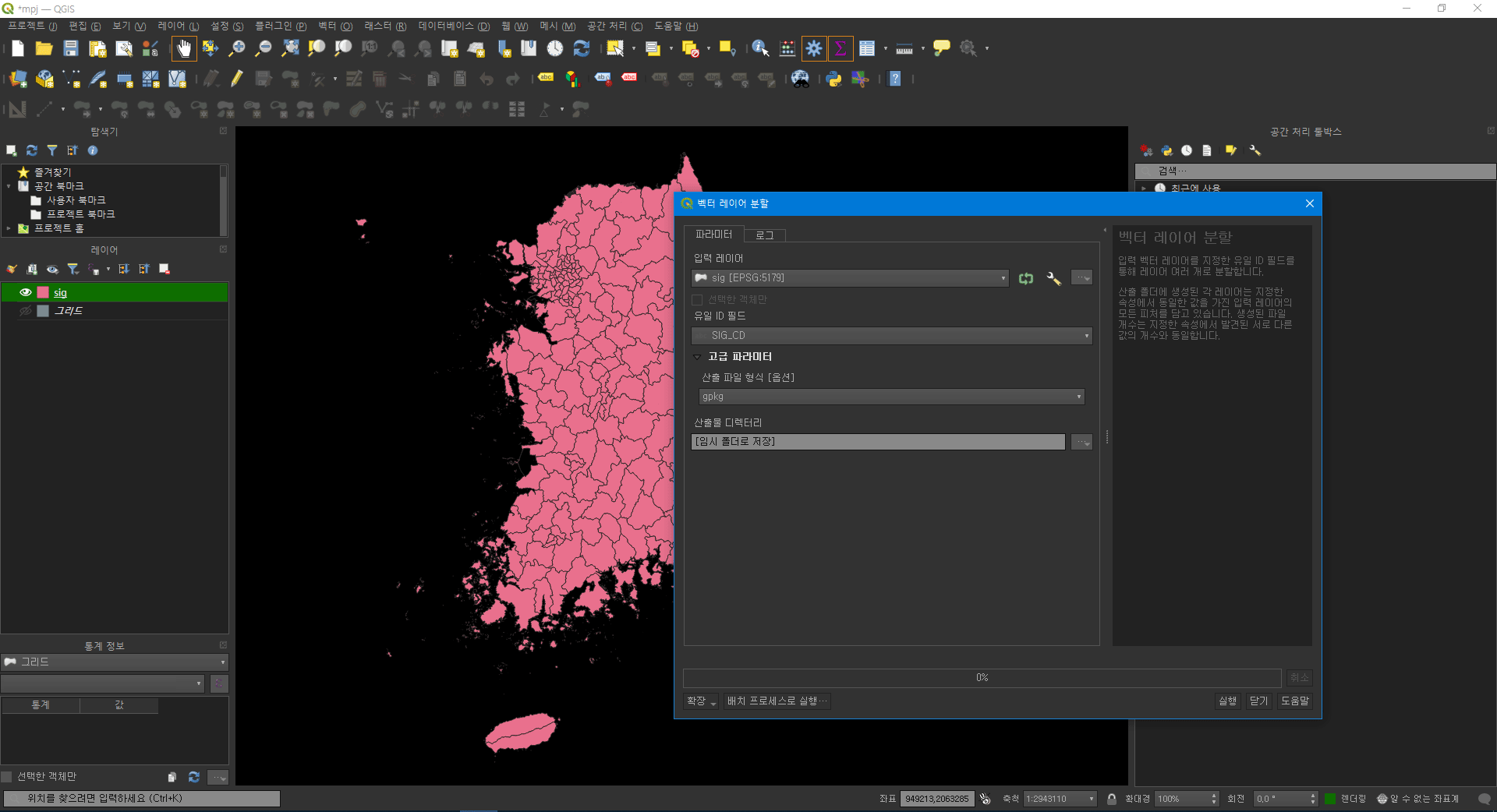
1.2. 레이어분할
이후 분석을 위해 벡터를 레이어 단위로 분리 후 QGIS로 다시 도입한다. 이때 키는 ID로 설정한다. ‘중구’와 같은 이름의 행정구역이 여러 개인 경우 오류가 발생하기 때문이다.
벡터 -> 데이터 관리 도구 -> 벡터 레이어 분할
1.3. 중첩 구역 분석
다음과 같이 그리드에 대한 모든 행정구역 레이어의 중첩영역을 분석한다.
공간 처리 툴박스 -> 중첩분석
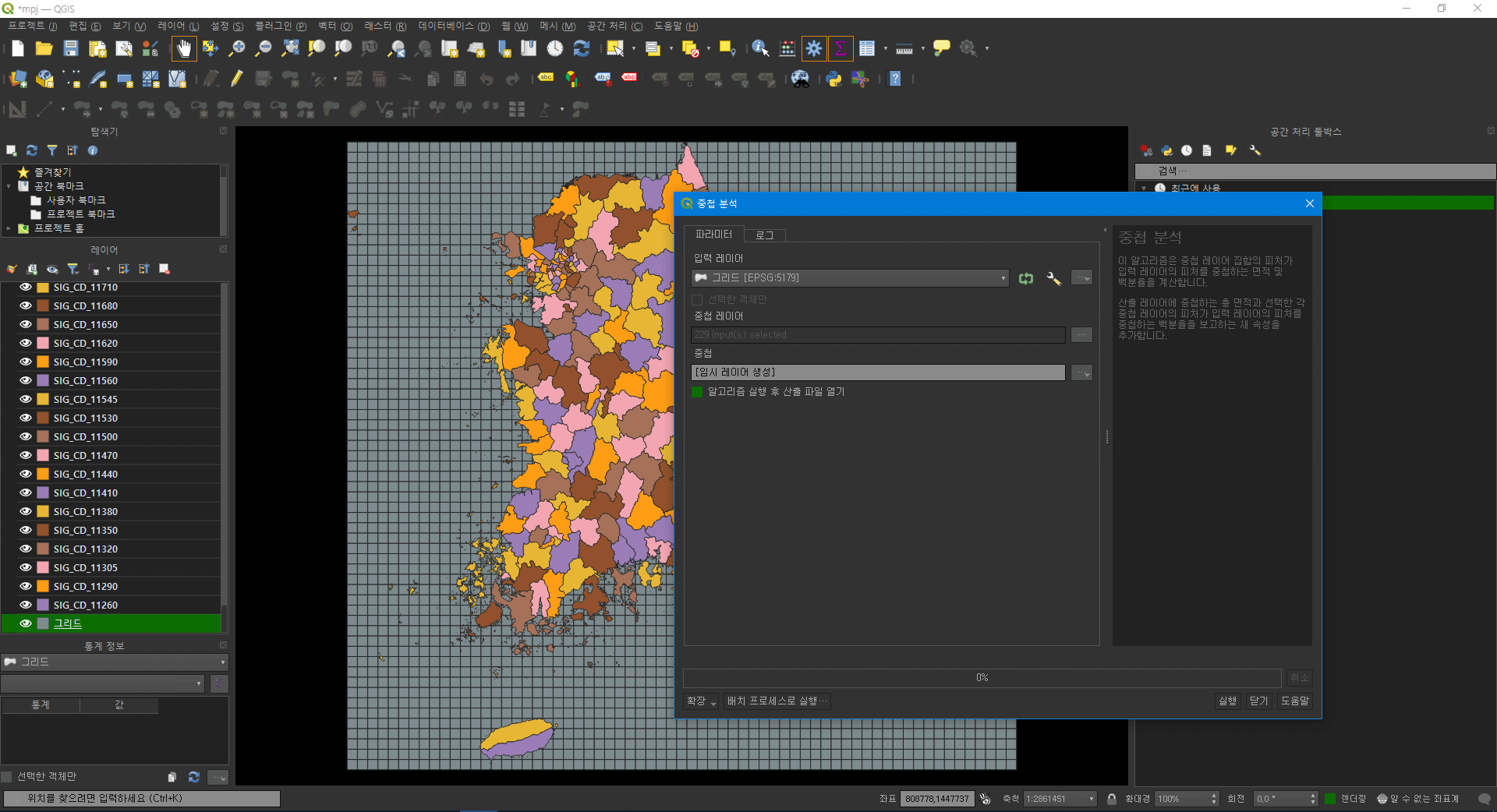
1.4. 파이썬 스크립트를 이용한 비율 기반 추출
분석 결과를 파이선에서 임포트하고 그리드의 셀에서 가장 높은 비율을 차지하는 행정구역의 키를 기록한다.
shp 파일에서 ‘(행정구역명)_pc’ 칼럼이 중첩비를 나타내므로 데이터프레임을 T 시킨후 max()를 사용하면 된다. 이후 키-행정구역 명칭-값 데이터프레임을 join 하여 지오데이터프레임을 기록한다.
원본 셰이프파일의 데이터는 다음과 같다고 가정할 경우
| gid | SIG_CD_11110_area | SIG_CD_11110_pc | … | geometry |
|---|---|---|---|---|
| 그리드ID | SIGCD11110영역 | SIGCD11110비율 | 나머지 SIG 레이어 정보 | 좌표정보 |
이 데이터에 SIG_CD_PC의 max()를 칼럼으로 붙이고 필요한 데이터만 추출하면 다음과 같은 데이터가 준비된다.
| gid | idx |
geometry |
|---|---|---|
| 그리드ID | 가장 비율이 높은 레이어 | 좌표정보 |
데이터를 다음과 같이 준비한 후 키를 기준으로 join후 Geodataframe으로 변환해 GIS 호환 파일로 저장한다.
idx |
admin_div | value | |
|---|---|---|---|
| 0 | SIG_CD_26110_pc | 중구(부산) | 41539 |
| 1 | SIG_CD_11110_pc | 종로구 | 148857 |
| 2 | SIG_CD_11140_pc | 중구(서울) | 126310 |
이하는 이를 구현한 스크립트의 예이다.
import pandas as pd
import geopandas as gpd
# 영역분석 결과 파일
gdf=gpd.read_file('export.gpkg')
# 주소키 주소 인구수 파일
addr_popu=pd.read_csv('data.csv',encoding='euc-kr')
# 인덱스 할당
pc_gdf=gdf.loc[:,gdf.columns.str.contains('_pc')]
idx=[(pc_gdf.iloc[x].idxmax()) if (pc_gdf.iloc[x].max()>1.) else 'none' for x in range(len(pc_gdf)) ]
gdf_out = gpd.GeoDataFrame(pd.concat([gdf[['gid']],pd.Series(idx),gdf['geometry']], ignore_index=True,axis=1), crs='epsg:5179')
gdf_out.columns=['gid','idx','geometry']
# 인덱스 키로 데이터 join
merged=pd.merge( pd.DataFrame(gdf_out),addr_popu,on='idx',how='left')[['gid','admin_div','value','geometry']]
merged.dropna(inplace=True)
# 데이터 저장
gdf_out = gpd.GeoDataFrame(merged, crs='epsg:5179')
gdf_out.to_file('results.gpkg')
완성된 파일에서 다음과 같이 행정구역에 해당하는 모든 그리드에 원하는 값이 매핑되어있음을 확인할 수 있다.
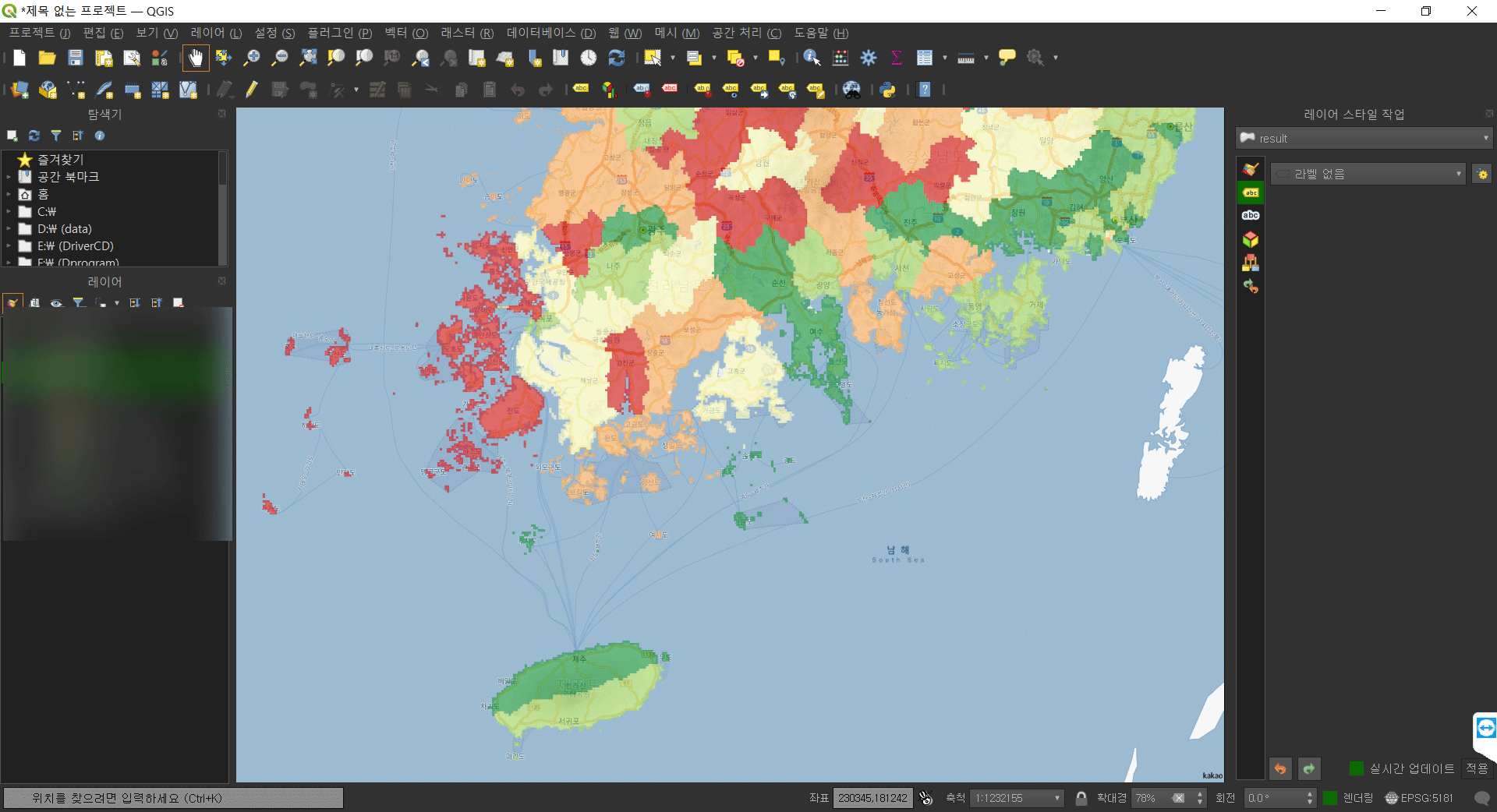
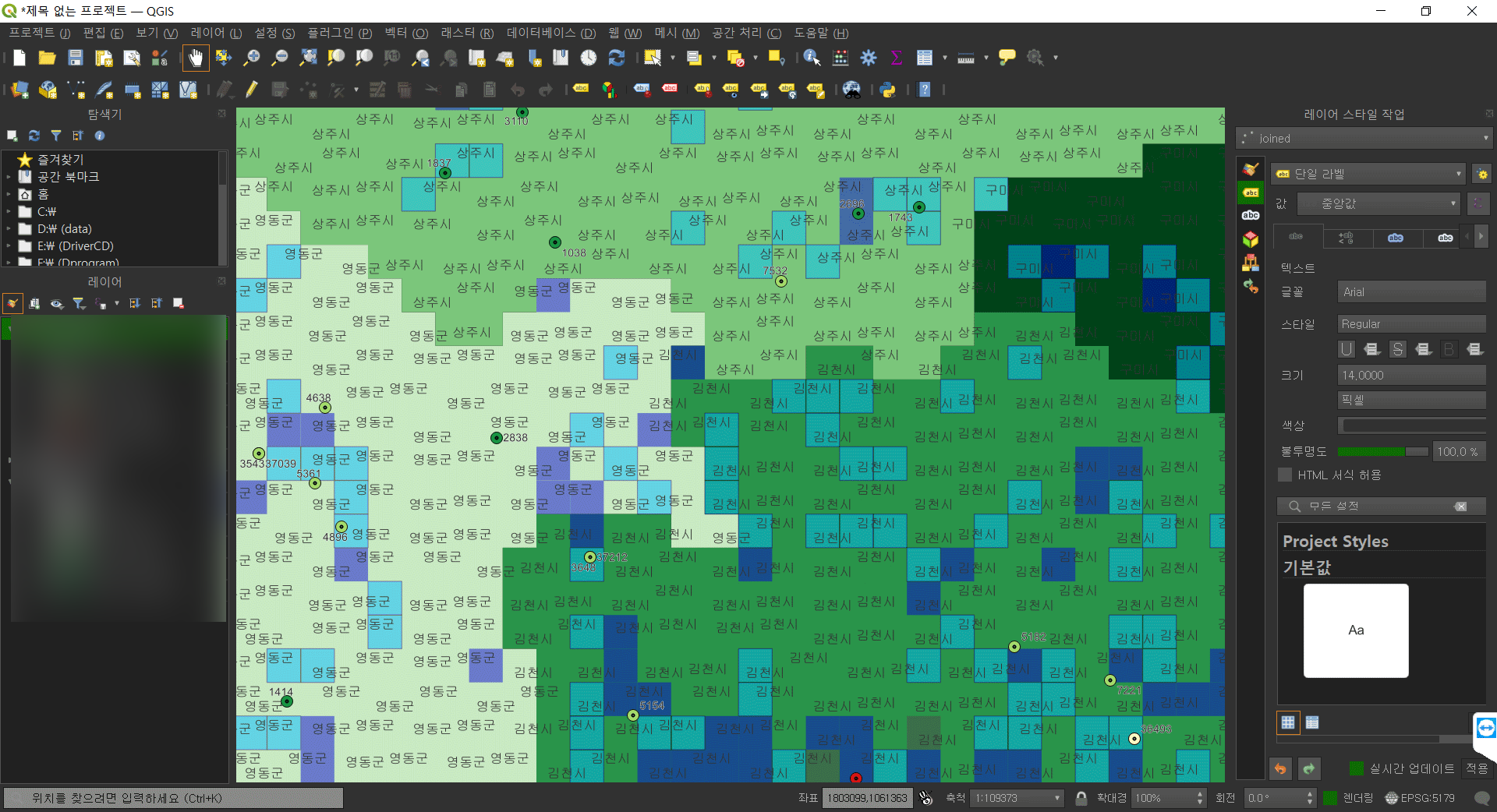
댓글남기기