
캡스톤디자인 중간발표[KNU 2022-1]
캡스톤디자인 중간발표
1
데이터 분석 현황 입니다.
첫 번째로 FLCS의 로직 개발안은 다음과 같습니다. FLCS의 입력 자료는 나사 LANCE FIRMS의 열점 좌표와 산림청 산불 관제 데이터로 구성됩니다. FIRMS는 이상 열측정치가 관측된 지점을 최소 1.5키로미터부터 최대 375미터의 해상도로 kml 파일를 제공합니다. 수신된 KML 데이터는 한반도를 포함하는 사각형 형태로 좌표만을 추출해 1차적으로 CSV 익스포트하게 됩니다. 산림청 산불 관제 데이터는 제이슨의 형식으로 수집되며 이 관제 정보는 산불의 발원지와 풍향, 풍속등의 부가적인 데이터를 가지고있습니다. 이러한 두 종류의 데이터는 프로토 타입 제작 기간동안 세시간의 인터벌로 수집되어 가공되어 분석용 PC에 전달됩니다.
분석의 단계에서는 임상도 데이터를 통하여 KMI의 좌표를 JOIN 처리 하게 됩니다. 이 과정을 통하여 국내 산림 데이터에 포함되는 kml 열원 데이터를 추출하게 되어 산에서 발생한 열원만을 필터링하게 됩니다. 이후 이 데이터는 머신러닝 모델 중 하나인 DBSCAN 알고리즘을 통해 유효 거리 내의 데이터를 클러스터링하는 절차를 거치게 됩니다. 이렇게 클러스터링 된 데이터는 convexhull 알고리즘 처리로 외곽선만을 추출하게 됩니다. 최종적으로 추출된 열원 데이터는 GeoJSON의 형태로 출력하게 되며 데이터베이스에 삽입됩니다. 산림청 산불관제의 JSON 데이터는 파싱을 통해 마커에서 사용할 정보를 추출하고 좌표계의 불안정으로 인해 모든 좌표데이터는 EPSG5179표준으로 통일하여 데이터베이스화 됩니다.
이렇게 처리를 끝낸 데이터는 통계청에서 제공하는 지리공간서비스 api인 sgis를 사용해 구현된 지도에서 출력 됩니다. 출력되는 데이터는 영역을 표시하기위한 GeoJSON상의 폴리곤외에 산불 상세 정보를 포함합니다.
2
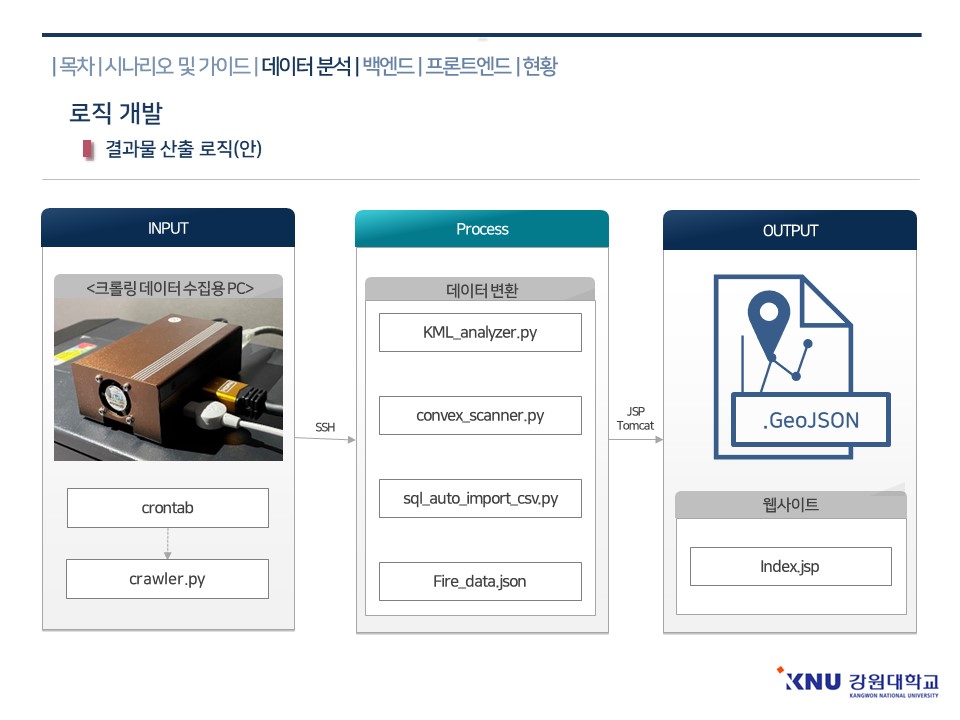
다음은 결과물 산출 프로세스입니다. 데이터 입력은 라즈베리파이로 제작된 데이터 수집용 pc로부터 매 3시간마다 데이터를 수신하게 되며 이는 리눅스 crontab에 의해 3시간마다 스케줄링된 파이썬 스크립트를 통해 수행됩니다. 데이터 수집용 pc로 부터 에서 수집된 데이터는 ssh 프로토콜을 사용하여 데이터 처리 및 서버 pc로 전달되고 이 pc는 데이터를 수신하는 즉시 데이터를 가공하게 됩니다.
프로세싱에서 사용되는 코드는 오류로부터 안정성을 보장하기위해 각 역할을 수행하는 모듈이 별개로 작성되었습니다. 대용량의 kml 데이터를 국내로 한정시켜 추출해 주는 ㅇㅇㅇㅇㅇㅇㅇㅇㅇ 클러스터링과 외곽선 처리를 담당하는 ㅇㅇㅇㅇㅇㅇㅇ 출력된 데이터를 sql로 삽입해주는 ㅇㅇㅇㅇㅇㅇㅇㅇ, 산림청 데이터의 파싱은 현재 준비중이므로 생략합니다. 데이터의 처리가 완료된 후 데이터베이스화된 결과물을를 가지게 되며 , 이는 JSP와 아파치 서버를 사용하여 인터넷상으로 출력할 수 있도록 구현합니다.
3
결과물 산출 프로세스에서 가장 중요한 DBSCAN 작업은 다음과 같이 수행됩니다. 노이즈가 아닌 산불 현상 즉, 클러스터로 분류하게 될 데이터의 최소값은 삼각형을 구성할 수 있는 3개의 인접 열원이며, 최대 간선 간 거리는 위경도 거리 환산 결과 1875미터 미만을 기준으로 하게 됩니다. 이 1875미터는 핀란드 npp 위성의 Visible Infrared Imaging Radiometer Suite 시스템이 측정 가능한 열점간 최소 거리인 375m와 산불 미국 산불통제기관에서 발표한 최대 불씨 비산거리인 1500미터를 합산한 결과입니다.
좌측하단은 적용한 DBSCAN알고리즘의 Sudocode로 위에서 언급 드린 최소 구성단위인 minpts와 간선 간 최대 거리인 e 값을 처리하는 과정으로 데이터셋의 모든 노드 클러스터 번호를 0으로 초기화하고 데이터셋의 모든 노드에 대해 반복하며 노드가 아직 클러스터링 되지 않았다면 그 노드를 핵심 노드로 지정하여 인접한 모든 노드를 재귀적으로 수집하며 수집된 노드 수가 minpts 이상이라면 클러스터번호를 할당합니다. 이 과정을 반복하며 모든 노드를 클러스터링 시도하며 마지막까지 클러스터번호 0로 남은 노드는 노이즈로 취급하여 맵에 나타나지 않게 됩니다.
오른쪽 사진은 이 과정을 도식화 한 자료입니다.
4
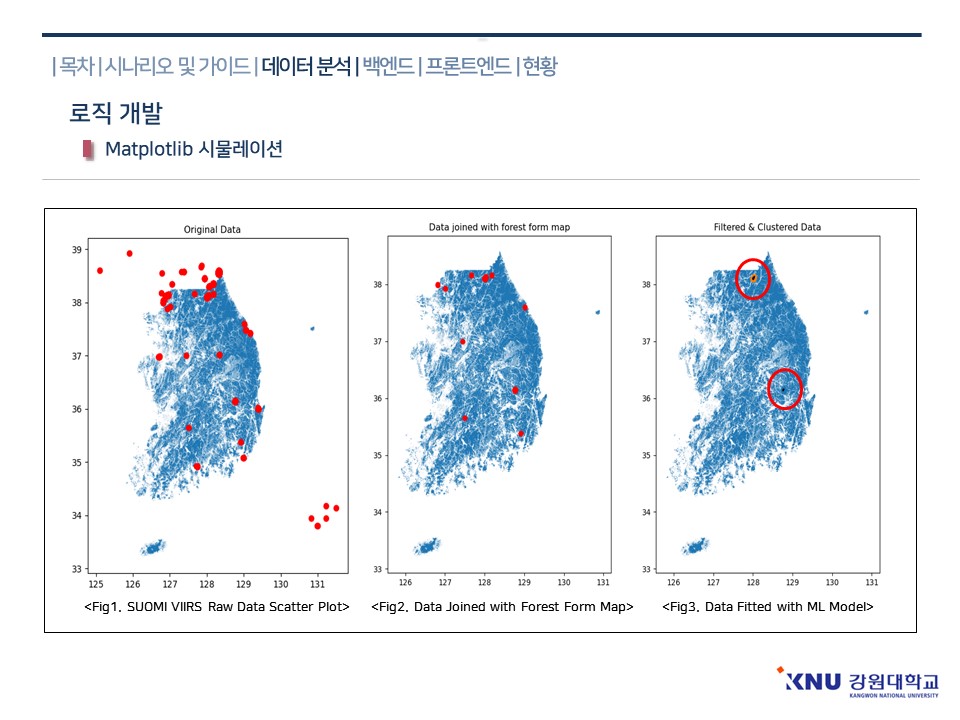
다음은 구현된 알고리즘으로 4월 10일의 데이터를 멧플롯립 시각화 한 결과입니다. 첫 번째 표는 한국에서 관측된 VIIRS의 raw 데이터를 스케터 플롯로 나타낸 결과입니다.
보시다시피 산이 아닌 지점에도 열원이 포착되는 경우 필터링 과정 없이 모든 점을 표시하게 되므로 발전소, 공장과 같은 열 방출 시설로 인해 산불만을 표출하는 데에 있어 정확도가 심각하게 떨어지게 됩니다.
다음으로 임상도를 사용하여 필터링한 결과입니다. 임상도는 현재 가장 정확한 자료인 산림청 제 5차 소축적 임상도를 활용하였습니다.
3번은 모델을 활용하여 데이터를 최적화한 결과입니다. 최종적으로는 두 개의 산불이 포착되었으며 상단의 산불은 양구군 산불, 두 번째 산불은 경북 군위군의 산불로 확인되었습니다.
5
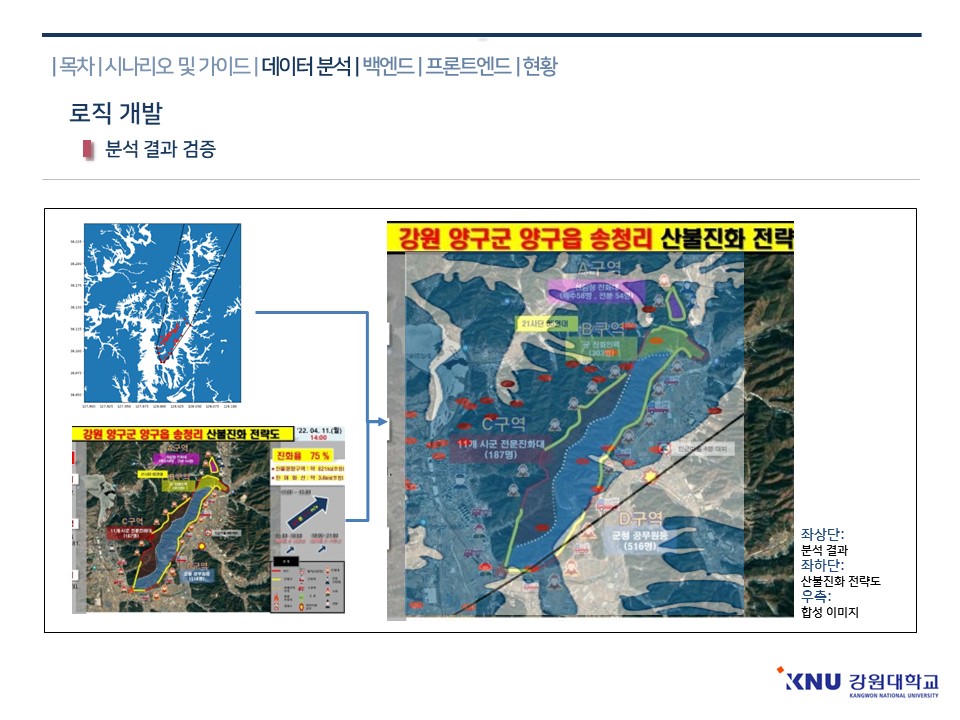
분석 결과 검증입니다. 좌상단 분석 결과, 좌하단 산불 진화 전략도, 우측 합성사진입니다. 유효 거리 내에서 산불 비교적 정확하게 포착할 수 있었음을 확인할 수 있었습니다.
6
다음은 경북 군위군 산불 분석 결과입니다. 위의 양구 분석 결과보다 훨씬 더 명확한 형태를 확인할 수 있었습니다.
7
데이터 엔지니어링 gis 담당자 향후 계획 및 보고 사항 입니다.
차후 개발 계획으로는 임상도 JOIN 연산 시 휴전선 이북의 지역 산불 정도의 산불 정보의 소실 문제를 해결하도록 하며 마커 데이터를 GeoJSON으로 통합해 단일 데이터베이스 테이블을 사용하도록 구현할 예정입니다. 또한 산림청 산불피해대장 상의 소실 면적과의 비교로 현 연구의 불일치률을 계산할 예정이며, 센티넬 2a 위성을 활용한 국내 선행 연구에서는 평균 12.23%의 참고 자료 불일치율을 보이고 있음을 확인해 모델의 피팅 개선을 통해 불일치율로 인한 최종 출력 오차를 최소화할 예정입니다.
근 실시간 자료 제공을 위한 보완 사항으로는 첫째, 기상위성인 천리안 2a이 해상도 2km인 ir밴드 조사 탑재체를 통해 10분 간격으로 지표면 온도를 관측하고 있으므로 저해상도 데이터를 사용해 필터링 구간의 조기 선정으로 데이터 수집의 시간 단축의 가능성을 확인했습니다. 둘째로, 현재 컴퓨터 엔진의 성능으로 인해 자료가 수집된 시간과 실제 서비스 반영의 시간과의 차이가 발생하고 있음을 확인하였으며. 쿠다 컴퓨팅 기술 또는 외부 컴퓨팅엔진의 활용으로 처리 시간 최소화의 가능성을 확인했습니다.
PPT




댓글남기기